If you run a JOIN or a GROUP BY in a database of your choice, there is a good chance that there is a hash table at the core of the data processing. At QuestDB, we have FastMap, a hash table used for hash join and aggregate handling. While high performing, its design is a bit unconventional as it differs from most general-purpose hash tables.
In this article, we'll tell you why hash tables are important to databases, how QuestDB's FastMap works and why it speeds up SQL execution.
Database + hash table = ❤️
QuestDB is an open-source time-series database that supports InfluxDB Line Protocol for fast streaming ingestion and SQL over Postgres wire protocol and HTTP for flexible and efficient querying. Like most SQL databases, we support JOINs:
SELECT e.first_name, e.last_name, c.name
FROM employees e
JOIN companies c
ON e.company_id = c.id;
The above query involves an implicit INNER JOIN and returns something like the following result set:
| first_name | last_name | name |
|---|---|---|
| John | Doe | Example Company |
| Jane | Doe | Example Company |
What exactly does the database do to return this result? There are multiple approaches to processing a JOIN, one of which is the so-called hash join.
To complete a hash join, we first iterate the joined table (companies in our example) and store all join key to row mappings in a hash table. Then, we can iterate the first table (employees) while using the hash table to find the joined rows:
public Row nextRow() {
// Build the hash table, if it's not already built.
if (!builtJoinTable) {
// The table holds company id to row pairs.
joinTable = new HashMap<Integer, Row>();
Row row;
while ((row = secondaryCursor.nextRow()) != null) {
joinTable.put(row.column("id"), row);
}
builtJoinTable = true;
}
// Iterate the first table while looking into the hash table.
Row row;
while ((row = primaryCursor.nextRow()) != null) {
Row joinedRow = joinTable.get(row.column("company_id"));
if (joinedRow != null) {
return mergeRows(row, joinedRow);
}
}
return null;
}
This is a simplified version of what pretty much any database does when it decides to execute a hash join. Notice that the hash table is used in a grow-only manner. This means that once data is added to the hash table, it is not removed or modified - the table will only grow in size.
As a result, we only see get()/put() operations, for retrieval and addition respectively. Needless to say, a fast hash table is essential for strong hash join performance.
Our second use case has to do with GROUP BY and SAMPLE BY, our time-series SQL extension. Let's count people with the same surnames with a simple GROUP BY:
SELECT last_name, count()
FROM employees
GROUP BY last_name;
The above query will return something like this:
| last_name | count |
|---|---|
| Doe | 2 |
Again, what kind of magic does the database do to process such a query? The answer is that, well, it uses a hash table:
public Row nextRow() {
// Build the group by table, if it's not already built.
if (!builtGroupByTable) {
// The table holds last_name to count pairs.
groupByTable = new HashMap<String, Integer>();
Row row;
while ((row = mainCursor.nextRow()) != null) {
String lastName = row.column("last_name");
Integer knownCount = groupByTable.get(lastName);
if (knownCount == null) {
groupByTable.set(lastName, 1);
} else {
groupByTable.set(lastName, knownCount + 1);
}
}
groupByCursor = groupByTable.cursor();
builtGroupByTable = true;
}
// Use a cursor over the hash table for the iteration.
return groupByCursor.nextRow();
}
Notice that we use a cursor over the hash table to traverse and iterate over the result set. Everything is straightforward:
- We store GROUP BY column values (last_name) as hash table keys
- Aggregate functions (count()) go to hash table values
Imagine that we run this query over a few hundred million rows. This means at least a few hundred million hash table operations. As you might imagine, a slow hash table would make for a slower query. A faster hash table? Faster queries!
We want a faster table. Let's discuss what makes FastMap different from a general-purpose data structure. The rest of the post assumes that you're familiar with hash table basics and design options, so if that's not the case, we recommend reading the Hash table Wikipedia page.
FastMap internals
Prefer to read the code? Jump over to FastMap in the QuestDB GitHub repository.
FastMap is written in Java and uses Unsafe heavily to store data outside of JVM's heap, in native memory.
At a glance, FastMap is just a hash table with open addressing and linear probing. The load factor is kept relatively low (0.7) and hash codes are cached to mitigate hash collision impact. Nothing surprising so far. The interesting part is that the hash table is grow-only, and supports var-size keys, but only fixed-size values.
FastMap consists of two main parts:
- An array of offsets and hash codes, i.e. the hash table itself
- a so-called heap, i.e. a grow-only chunk of native memory
These two parts can be illustrated with the following diagram:
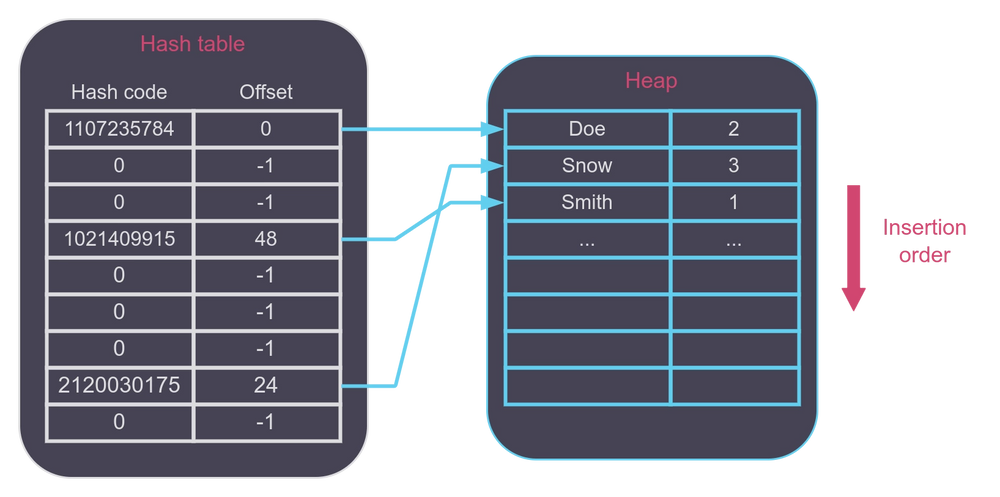
Note that we use the "heap" word for a grow-only contiguous chunk of native memory used to store FastMap's key-value pairs, not JVM's heap.
Each offset value is a compressed 32-bit offset pointing at a key-value pair stored in the heap. Key-value pair addresses are 8 byte-aligned, hence we can compress 35-bit offsets to 32-bit. This means that a FastMap is capable of holding up to 32GB of data. Interestingly, OpenJDK does a similar trick with object pointers on 64-bit systems when CompressedOops feature is enabled.
Since offsets aren't memory addresses, but address deltas, they remain the same if the heap is reallocated. In other words, there is no need to update the offsets when the heap needs to grow.
The heap itself contains key-value pairs stored in insertion order. Thanks to our SQL use cases, we can limit FastMap to grow-only API. In other words: It only supports insert and update operations, but doesn't support key deletion.
As a result, we don't need to deal with tombstones and periodical heap compaction. Once a SQL query execution finishes, we can simply zero the offsets array and treat the heap as empty.
Each key-value pair stored on the heap has the following layout:
| length | Key columns 0..K | Value columns 0..V |
+----------------------+------------------+--------------------+
| 4 bytes | - | - |
+----------------------+------------------+--------------------+
The key length is stored in bytes at the entry header, allowing for quick navigation to the value. This is particularly useful for variable-size keys, such as a single STRING column value. Following the header, the pair memory contains all key column values (similar to fields), and then the value column values.
FastMap is designed to support only fixed-size values, such as multiple INT columns. This design choice leads to simplified updates to the value when necessary.
Another nice side effect of this indirection with the heap is the guaranteed insertion order on hash table iteration. Most hash tables have no iteration order guarantees due to the nature of hash functions. But FastMap is different.
If you insert "John" and then "Jane" string keys into a FastMap, then that would later become the iteration order. While it doesn't sound like a big deal for most applications, this guarantee is important in the database world.
If the underlying table data or index-based access returns sorted data, then we may want to keep the order to avoid having to sort the result set. This is helpful in case of a query with an ORDER BY clause. Performance-wise, direct iteration over the heap is also beneficial as it means sequential memory access.
The hash function used in FastMap is also somewhat unconventional. We took a long path using Java String's hash function (the polynomial hash function from The C Programming Language book by Kernighan & Ritchie), then xxHash64, then another polynomial function inspired by this Peter Lawrey's post:
private static final long M2 = 0x7a646e4d;
public static int hashMem32(long ptr, long len) {
long h = 0;
int i = 0;
for (; i + 7 < len; i += 8) {
h = h * M2 + Unsafe.getUnsafe().getLong(ptr + i);
}
if (i + 3 < len) {
h = h * M2 + Unsafe.getUnsafe().getInt(ptr + i);
i += 4;
}
for (; i < len; i++) {
h = h * M2 + Unsafe.getUnsafe().getByte(ptr + i);
}
h *= M2;
return (int) h ^ (int) (h >>> 32);
}
Here we calculate the hash code first in 8-byte chunks (long type), then in 4 bytes (int) and, finally, byte-by-byte. This provides much better speed than a single byte-size loop and is known as the SWAR technique.
Yes, this function has a worse quality than xxHash, but this is mitigated by its compactness and the fact that we cache hash codes. A small executable is important for smaller keys.
A function that occupies many i-cache lines may show worse results than a simpler one. Unless hash code calculation in a tight loop is everything that your code does, a more complex hash function with better quality is not necessarily better (wink-wink benchmarks that show impressive hash function throughput).
Remember how we also cached hash codes for the inserted keys? Thanks to that, we don't need to re-calculate them on look-ups, saving precious CPU cycles for more important things.
But is all the complexity worth it? Why not just use a good old java.util.HashMap from the standard Java library? Let's run a few microbenchmarks to compare them. The first benchmark verifies how long it takes to look up a short string key in a hash map:
Benchmark Mode Cnt Score Error Units
FastMapReadBenchmark.testFastMap avgt 3 0.309 ± 0.009 us/op
FastMapReadBenchmark.testHashMap avgt 3 0.367 ± 0.003 us/op
On average it takes 309 nanoseconds for FastMap to find the value for the given key while for HashMap it takes 367 nanoseconds.
The next benchmark tests how long it takes to insert a string key in a map:
Benchmark Mode Cnt Score Error Units
FastMapWriteBenchmark.testFastMap avgt 3 0.340 ± 0.015 us/op
FastMapWriteBenchmark.testHashMap avgt 3 0.572 ± 0.055 us/op
Again, FastMap is slightly faster than HashMap which is significant considering that the standard hash table had a long optimization path across so many Java versions. QuestDB's hash table also has the advantage of being zero-GC. It doesn't put any pressure on the garbage collector since the data is stored off-heap.
For those who want to run the benchmarks and compare the results, in this case we used Ubuntu 22.04, OpenJDK 64-bit 17.0.8.1, and an Intel i7-1185G7 CPU to get the results.
While we have the microbenchmarks in place, we prefer relying on the query execution times as the primary metric. With some of the described FastMap enhancements landing in QuestDB recently, we reduced GROUP BY / SAMPLE BY query execution times by 20-30%.
What's next?
So, is QuestDB's FastMap the best thing since sliced bread? Of course, it's not. As with everything in engineering, it's a matter of trade-offs. FastMap works nicely for us, but it doesn't mean that it would be a good choice for, say, a web application or even for another database. Besides that, there are always some things to be optimized and improved. For example, the so-called disk spill could be added to FastMap to handle huge join situations.
N.B. Thanks to the valuable feedback we received from the community after publishing this post, we've started experimenting with further optimizations. The most noticeable one is Robin Hood hashing, a linear probing enhancement aimed to minimize the number of look-up probes for the keys. If you prefer jumping to the code, the pull request is here.
As usual, we encourage you to try the latest QuestDB release and share your feedback with our Community Forum. You can also play with our live demo to see how fast it executes your queries.